 咨询电话:400-123-4567 咨询电话:400-123-4567
咨询电话:400-123-4567 咨询电话:400-123-4567 



 全国免费客服电话 400-123-4567
全国免费客服电话 400-123-4567 邮箱:admin@youweb.com
手机:13800000000
电话:400-123-4567
地址:广东省广州市天河区88号
发布时间:2024-04-29 03:23:30 人气:
梯度下降法是最早最简单,也是最为常用的最优化方法。梯度下降法实现简单,当目标函数是凸函数时,梯度下降法的解是全局解。一般情况下,其解不保证是全局最优解,梯度下降法的速度也未必是最快的。梯度下降法的优化思想是用当前位置负梯度方向作为搜索方向,因为该方向为当前位置的最快下降方向,所以也被称为是”最速下降法“。最速下降法越接近目标值,步长越小,前进越慢。在机器学习中,基于基本的梯度下降法发展了两种梯度下降方法,分别为随机梯度下降法和批量梯度下降法。
比如对一个线性回归(Linear Logistics)模型,假设下面的h(x)是要拟合的函数,J(theta)为损失函数,theta是参数,要迭代求解的值,theta求解出来了那最终要拟合的函数h(theta)就出来了。其中m是训练集的样本个数,n是特征的个数。

批梯度下降 BGD(Batch Gradient Descent)

或者把1/m 用步长a代替。
(3)从上面公式可以注意到,它得到的是一个全局最优解,但是每迭代一步,都要用到训练集所有的数据,如果m很大,那么可想而知这种方法的迭代速度会相当的慢。所以,这就引入了另外一种方法。
随机梯度下降(stochastic gradient descent) or 增量梯度下降(incremental gradient descent)


(3)随机梯度下降是通过每个样本来迭代更新一次,如果样本量很大的情况(例如几十万),那么可能只用其中几万条或者几千条的样本,就已经将theta迭代到最优解了,对比上面的批量梯度下降,迭代一次需要用到十几万训练样本,一次迭代不可能最优,如果迭代10次的话就需要遍历训练样本10次。但是,SGD伴随的一个问题是噪音较BGD要多,使得SGD并不是每次迭代都向着整体最优化方向。
随机梯度下降每次迭代只使用一个样本,迭代一次计算量为n2,当样本个数m很大的时候,随机梯度下降迭代一次的速度要远高于批量梯度下降方法。两者的关系可以这样理解:随机梯度下降方法以损失很小的一部分精确度和增加一定数量的迭代次数为代价,换取了总体的优化效率的提升。增加的迭代次数远远小于样本的数量。
对批量梯度下降法和随机梯度下降法的总结:
批量梯度下降—最小化所有训练样本的损失函数,使得最终求解的是全局的最优解,即求解的参数是使得风险函数最小,但是对于大规模样本问题效率低下。
随机梯度下降—最小化每条样本的损失函数,虽然不是每次迭代得到的损失函数都向着全局最优方向, 但是大的整体的方向是向全局最优解的,最终的结果往往是在全局最优解附近,适用于大规模训练样本情况。
首先,选择一个接近函数 f (x)零点的 x0,计算相应的 f (x0) 和切线斜率f ’ (x0)(这里f ’ 表示函数 f 的导数)。然后我们计算穿过点(x0, f (x0)) 并且斜率为f '(x0)的直线和 x 轴的交点的x坐标,也就是求如下方程的解:
我们将新求得的点的 x 坐标命名为x1,通常x1会比x0更接近方程f (x) = 0的解。因此我们现在可以利用x1开始下一轮迭代。迭代公式可化简为如下所示:
已经证明,如果f ’ 是连续的,并且待求的零点x是孤立的,那么在零点x周围存在一个区域,只要初始值x0位于这个邻近区域内,那么牛顿法必定收敛。 并且,如果f ’ (x)不为0, 那么牛顿法将具有平方收敛的性能. 粗略的说,这意味着每迭代一次,牛顿法结果的有效数字将增加一倍。 由于牛顿法是基于当前位置的切线来确定下一次的位置,所以牛顿法又被很形象地称为是"切线法"。
从本质上去看,牛顿法是二阶收敛,梯度下降是一阶收敛,所以牛顿法就更快。如果更通俗地说的话
,比如你想找一条最短的路径走到一个盆地的最底部,梯度下降法每次只从你当前所处位置选一个坡度最大的方向走一步,牛顿法在选择方向时,不仅会考虑坡度是否够大,还会考虑你走了一步之后,坡度是否会变得更大。所以,可以说牛顿法比梯度下降法看得更远一点,能更快地走到最底部。

推广为向量的情况

其中表达式中
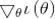
表示的?(θ)对的偏导数;H是一个n*n的矩阵,称为Hessian矩阵。Hessian矩阵的表达式为:

牛顿法的优缺点总结:
优点:二阶收敛,收敛速度快;
缺点:·牛顿法要求计算目标函数的二阶导数(Hessian matrix),在高维特征情形下这个矩阵非常巨大,计算和存储都成问题
·在使用小批量情形下,牛顿法对于二阶导数的估计噪音太大
·在目标函数非凸时,牛顿法更容易收到鞍点甚至最大值点的吸引
拟牛顿法(Quasi-Newton Methods)
拟牛顿法的本质思想是改善牛顿法每次需要求解复杂的Hessian矩阵的逆矩阵的缺陷,它使用正定矩阵来近似Hessian矩阵的逆,从而简化了运算的复杂度。拟牛顿法和最速下降法一样只要求每一步迭代时知道目标函数的梯度。通过测量梯度的变化,构造一个目标函数的模型使之足以产生超线性收敛性。这类方法大大优于最速下降法,尤其对于困难的问题。另外,因为拟牛顿法不需要二阶导数的信息,所以有时比牛顿法更为有效。如今,优化软件中包含了大量的拟牛顿算法用来解决无约束,约束,和大规模的优化问题。
常用的拟牛顿法有DFP算法和BFGS算法(http://blog.csdn.net/qq_27231343/article/details/51791138)
共轭梯度法是介于最速下降法与牛顿法之间的一个方法,它仅需利用一阶导数信息,但克服了最速下降法收敛慢的缺点,又避免了牛顿法需要存储和计算Hesse矩阵并求逆的缺点,共轭梯度法不仅是解决大型线性方程组最有用的方法之一,也是解大型非线性最优化最有效的算法之一。 在各种优化算法中,共轭梯度法是非常重要的一种。其优点是所需存储量小,具有步收敛性,稳定性高,而且不需要任何外来参数。
(https://en.wikipedia.org/wiki/Conjugate_gradient_method#Example_code_in_MATLAB)

启发式方法指人在解决问题时所采取的一种根据经验规则进行发现的方法。其特点是在解决问题时,利用过去的经验,选择已经行之有效的方法,而不是系统地、以确定的步骤去寻求答案。启发式优化方法种类繁多,包括经典的模拟退火方法、遗传算法、蚁群算法以及粒子群算法等等。
还有一种特殊的优化算法被称之多目标优化算法,它主要针对同时优化多个目标(两个及两个以上)的优化问题,这方面比较经典的算法有NSGAII算法、MOEA/D算法以及人工免疫算法等。
我们已经知道梯度下降法,需要沿着整个训练集的梯度反向下降。使用随机梯度下降方法,选取小批量数据的梯度下降方向,可以在很大程度上进行加速。SGD及其变种可能是机器学习中应用最多的优化算法。我们按照下面的顺序一一理解一下这些算法。
SGD->SGDM->NAG->AdaGrad->RMSProp->Adam->Nadam
1、随机梯度下降(SGD)
核心是按照数据生成分布抽取m个小批量样本,通过计算它们的梯度均值,来得到整体梯度的无偏估计。

SGD最大的缺点是下降速度慢,而且可能在沟壑的两边持续震荡,停留在一个局部最优点。
2、使用动量的随机梯度下降(SGDM)
动量方法旨在加速学习,特别是处理高曲率、小但一致的梯度,或带噪音的梯度。动量积累了之前梯度指数级衰减的移动平均,并且继续沿该方向移动。可以这么理解:为了避免SGD震荡,SGDM认为梯度下降过程可以加入惯性,下坡的时候如果发现是陡坡,就利用惯性跑的远一点。也就是说梯度下降的方法不仅由当前的梯度方向决定,还由此前积累的下降方向决定。
这里用速度变量 vv 来表示负梯度的指数衰减平均,超参数 α∈[0,1)α∈[0,1) 决定了之前梯度的贡献衰减得有多快。更新规则如下:

3、使用Nesterov动量的随机梯度下降(NAG)
这是SGD-M的一种变体,用于解决SGD容易陷入局部最优的问题。通俗的理解是:但陷入局部最优时,我们不妨向前多走一步,看更远一些。我们知道动量方法中梯度方向由积累的动量和当前梯度方法共同决定,与其看当前梯度方向,不妨先看看跟着积累的动量走一步是什么情况,再决定怎么走。更新规则如下:

4、AdaGrad
我们知道SGD算法中的一个重要参数是学习率,它对模型的性能有着显著的影响。那么在整个学习过程中自动适应这个学习率才是正确的做法。
AdaGrad算法的做法是:缩放每个参数反比于其所有梯度历史平方值总和的平方根。具有损失最大偏导的参数相应的有个快速下降的学习率,小偏导的参数具有较小的学习率。效果是在参数空间中更为平缓的倾斜方向会取得更大的进步。
通俗的理解是:对于经常更新的参数,我们已经积累的大量关于它的知识,不希望被单个样本影响太大,所以学习率慢一点;对于偶尔更新的参数了解信息少,希望从样本中多学习点,即学习率大一点。我们用积累的所有梯度值的平方和来度量历史更新频率。
5、AdaDelta/RMSProp
AdaGrad单调递减的学习率边化过于激进,RMSProp通过:不积累全部历史梯度,而引入指数衰减平均来只关注过去一段时间的下降梯度,丢弃遥远过去的历史梯度。
6、Adam
我们总结上面的算法可以发现:SGD作为最初的算法,SGDM在其基础上加入了一阶动量(历史梯度的累计),AdaGrad和RMSProp在其基础上加入了二阶动量(历史梯度的平方累计),那么Adam就是自适应?动量了,其在SGD基础上加入了一、二阶动量。
7、最后Nadam就是Adam基础上按照NAG计算梯度的变体。
相关推荐
服务热线


